
| Многопоточность: получилось-6 (01.07.2025). |
|
| 2026 - Июль |
| 01.07.2026 09:23 |
|
Материалов на тему многопоточности и параллелизма было много. Казалось бы, всё исчерпано. Однако как только потребовалось не просто простые числа считать, а погрешности с точностью до 10-19, - тут-то ещё нюансы и поплыли. А когда ещё и на разных ПК работоспособность начала проверяться - так вообще караул.
Предыстория и развитие событий: - необходимость разработки генератора площадных зон на карте планеты; - необходимость считать погрешность расчётов уравнений прямых с реверсивными вычислениями (оценка надёжности генератора); - перенос наработок из прошлого проекта; - определение погрешности расчёта при использовании long double для одного уравнения прямой, но с малой точностью (дискрет 1град при наклоне прямых); - необходимость оптимизации исходников при критерию скорости - пока мозги из ушей не вытекут: параллелизма не хватает для увеличения точности вычислений за приемлемое время. Развитие событий привело к окончательному пониманию: - без корректно работающей заготовки по параллелизму - невозможно выполнить задачу быстро и корректно (в т.ч. из-за забывания его тонкостей работы). Наработки прошлого проекта пришлось допиливать и выносить в отдельные файлы - именно для того, чтобы потом можно было их подключить к любому проекту, переименовать функции в соответствии с назначением и идти пить чай. И то, сейчас итоговый вариант еще не сделан: например, механизм слежения за потоками был полностью переписан - но недостаточно оптимизирован по разным критериям; - создание приложения с параллелизмом - с нуля невозможно. Сначала должен быть написан однопоточный исходник, который с корректностью 100% что-то делает. Зацепившись за результаты работы однопоточного исходника (в данном случае, максимальное число k в уравнениях прямой и максимальная найденная погрешность) - исходник переписывается как многопоточный для каждого потока, с целью получить эти-самые числа за меньшее время; - потоковый исходник отличается от однопоточного: негативно по критерию объёма кода и скорости работы. Имея работающий однопоточный исходник со временем работы 2080с, не удалось выжать из потокового исходника, работающего в одном потоке, менее 2140с. В свою очередь, в однопоточном исходнике время 2080с было получено путём многократной оптимизации, начиная со времени 6ч; - как ни извращайся, родительский поток замедляет дочерние. В итоге, 2140с были уменьшены всего до 340с - не в теоретические 11 раз. Ещё совершаются попытки как-то уменьшить это влияние, но вероятность успеха уже низкая; - никогда степень загрузки ЦП не является индикацией быстрых вычислений. Можно накодить так, что скорость окажется меньше однопоточного варианта (например, без ProcessMessages() в родительском потоке) - при загрузке ЦП 100%. Тонкости, возникшие при разработке и тестировании: - судя по диспетчеру задач, потоки с одним и тем же заданием (разница только в номиналах в первом цикле for - но при одинаковости количества итераций в нём) - выполняются за разное время (хотя предполагалось обратное: примерно одинаковое время). Полная хаотичность как номера потока, так и времени их работы (первый поток может кончаться на отметке 80-99% времени работы последнего). Изначально предполагалось, что более большие числа обрабатываются медленнее малых, - однако именно механизм слежения за потоками показал: и разбиение одной задачи на части для каждого потока корректное, и не в номинале чисел дело; - к хаосу добавляется общее время выполнения всех потоков (всей задачи): плавает 270-410с - сами думайте, чем это вызвано на ПК, на котором нет ничего кроме голой ОС и дров, в которой ничего не запущено; - формулам разбиения одной задачи на части, несмотря на их простоту, нужно уделить пристальное внимание. Дискрет работы однопоточного цикла было 360000, а потоков было 11, - нужно выводить уникальные числа для каждого потока, имитируя другое количество потоков, - проверяя их на полную корректность; - изначально Terminate() потока работал корректно только внутри дочернего потока, не работая из массива потоков родительского потока. Удалось переломить ситуацию путём искусственного ограничения: исходный код дочернего потока никогда не будет выполнен до конца - while (true) Sleep(1000); - со Sleep() очень неоднозначная ситуация (оптимальное число для родительского потока - 100). Она приводит к простою дочернего потока (нет нагрузки) - но не приводит к простою родительского (в диспетчере задач всегда 99-100% загрузки ЦП при загрузке всех потоков). Устраняет лаги родительского потока (форма перестаёт лагать) при работе механизма слежения за потоками (влияние дочерних потоков на родительский через свои переменные?!) - но никак не ускоряет дочерние потоки (думалось, что дочерние потоки влияют друг на друга, - однако разницы между Sleep() и сразу Terminate() нет); - не исключено влияние всех потоков друг на друга, иначе как такой хаос со временами их выполнения объяснить (разницей частот потоков, постоянно плавающих и наблюдаемых в HWiNFO, - да не то пальто). Влияние, наверняка, нелинейное и хаотичное от запуска к запуску; - запуск на разных ПК ещё больше путаницы вносит (при клонированной ОС и одинаковой по ТТХ и объёму RAM). ЦП i5-10400 отсасывает у i7-8700 и по частоте (-300МГц), и по разгону (-300МГц), и не имеет технологии TSX (направленной на ускорение параллелизма - какого хрена её из новых ЦП начали убирать: опять какая-нибудь охранота настояла?). Но при этом у i7-8700 время выполнения 400с против 340с у i5-10400. Тут точно что-то с настройками BIOS и тонкостями разгона связано (отключен может быть: у i5-10400 - разгон-подделка, одного ядра); - сунулся в BIOS в настройки ЦП - отключение C1E, включение переопределения динамического коэффициента - практически сравняли скорости двух ЦП. Можно ли считать последнюю опцию алиасом TSX - непонятно. Реверсивные вычисления: отключаю переопределение - скорость увеличилась ещё больше - вообще ничего не понятно. Возможно, скорость меняется от перезагрузки, предпочтений винды и излучения планеты Нибиру (скорее всего, опять разброс скорости 21% играет роль - и первые замеры оценки скорости двух ЦП есть тупо совпадение); - то есть, программно-аппаратная настройка ПК для наиболее быстрого параллелизма - ещё одно болото по тематике многопоточного программирования. И с учётом хаоса в программной части - как бы до обратной сикофантии не скатиться от человека к CPU. Теперь пора запускать тест: для расчёта погрешности уравнений прямых выше точности 1град в 10 раз - 6мин. С учётом увеличения числа измерений в 10000 раз - результат будет получен где-то в августе (~40дн - а счёт за электричество при полной загрузке ЦП представляете?). (добавлено 02.07.2026) Серверный E5-2696 V2 - в очередной раз ушатал i5-10400: 200с на ту же работу. Потом было найдено решение, уменьшающее влияние родительского потока на дочерние. Sleep(100) и ProcessMessages() - надо писать не после цикла анализа состояния потоков, а непосредственно после анализа каждого потока (и 100 заменить на 10). Как только это произошло - i5-400 начал выдавать среднее значение 292с вместо 340с. Но это решение обнажило страшный баг, в очередной раз доказывающий: если хоть одна строчка при параллелизме неверна - всё идёт годзилле под хвост. Время, затрачиваемое на вторую обработку вычислений, всегда стало сильно больше первой - процентов на 20-40. С помощью диспетчера задач выяснилось: потоки не освобождаются (перестала работать FreeOnTerminate = true). Какие только игры не делал с Free(), Terminate(), FreeOnTerminate, в родительском и дочернем потоках - либо потоки копятся (и разом, например, 55 потоков удаляются в диспетчере задач после выхода из ПО), либо Free() вызывает зависание исходников где-то внутри себя. Увеличенное время - первые дочерние 11 потоков, даже находясь после работы в покойном Sleep(квадриллион) и даже после Terminate(), - влияют на новые созданные 11. При этом, третий и последующие запуски не увеличивают время в прогрессии - оставляя его на том же уровне (с тем же разбросом - со средним 340с). Ужас и в том, что даже деструктор потока вызывает такое же зависание, как и Free(). То есть, добился ускорения только при первом нажатии на кнопку вычислений. Невозможно проверить корректность Free() потока. Указатель на поток всё равно остаётся - а методов проверки вида IsFree(), IsTerminate() не существует. Может, Free работает нормально и всегда выполняется при Terminate() - просто есть ещё какой-то баг: что-то после этих потоков подчищать надо - и ОС тогда по подчищенному поймёт и удалит эти потоки окончательно. (добавлено 03.07.2026) И проблема плавающего времени (погрешность стала <3%), и проблема Free() (корректное доудаление потоков) - были решены. Время заявить о себе как о гении, сравнимым с капитаном Джеком Воробьём, - однако параллелизм никогда не отступает: время выполнения вычислений на самом слабом ЦП стало самым малым (260с), а время на самом сильном стало вместо 200с - 296с. Это уже - полный сюр и дичь; что изменилось - совершенно непонятно. И надо рыть дальше. Пока только памятку, написанную за вчерашний день, выложить смысл есть (и исходники, когда всё будет кончено). /* Важно! Свойства и методы потоков неочевидны, равно как взаимодействие потоков с операционной системой. Если вы не прочитаете это предисловие - вы при создании своего проекта вообще ничего не поймёте, будете окружены ложноистинными суждениями. Диспетчер задач ОС, вкладка "Производительность": - может показывать все логические процессоры (реальные в физическом мире потоки ЦП); - показывает общее количество потоков (у 100+ приложений) - оно постоянно меняется; - если одновременно создать много потоков - виден скачок на примерно нужное число; - если выйти из приложения - обратный скачок: система сама подчищает за говнокодером; - номер логического процессора (потока ЦП как физической его ТТХ) никогда не равен номеру цифрового потока; - вкладка "Подробности" неверно отражает количество потоков процесса (в рамках данной задачи), но за дельтой этого числа следить удобнее; - значение загрузки ЦП во вкладке "Подробности" - не соответствует загрузке во вкладке "Производительность". Создание потоков: - оптимальное число: количество логических процессоров минус 1: родительский и дочерние. Остаётся разбросать задачу равными кусками в каждый поток с одинаковой функцией обработки данных; - в класс потока, как в любой другой класс, можно дописывать свои свойства и методы; - создание потоков - в массив потоков: чтобы организовать слежение за ними (без слежения ни тонкостей работы не понять, ни что вообще происходит в текущий момент). Слежение за потоками (выявлены сильные баги потоков): - свойства bBusy и iThread_Number - необходимый минимум и для слежения за нагрузкой потока, и для создания уникальных данных для каждого потока; - родительский поток влияет на дочерние. Механизм слежения адаптирован так, чтобы это влияние было минимальным, - каждое число и расположение функций выстрадано временем; - дочерние потоки влияют друг на друга. Если не уничтожить предыдущие даже простаивающие потоки, даже после Terminate(), - они начинают тормозить текущие нагруженные; - при равных данных и вычислениях: каждый поток работает со своей скоростью - вплоть до времени окончания работы 10-го потока на 80-м проценте времени работы 3-го; - соответственно, сильно пляшет и итоговое время выполнения всей задачи. Очищение потока (выявлены жуткие баги): - если поток завершил свой код - он сам вызывает себе Free() (видно в диспетчере задач); - при этом, ему абсолютно насрать на значение FreeOnTerminate (хотя он, по логике, сам себя прерывает для успешного Free()); - при этом, все его свойства остаются доступными (и указатель, и объект потока - сохраняются, но запустить поток уже не получится); - при этом, приложение может не закрываться крестиком - значит, этот Free() не до конца; - при этом, приложение может следующую порцию потоков сформировать так, что зависнет вообще вся ОС: - вплоть до отключения светодиода мыши - несколько раз было; - отвисает с большим временем ожидания - дочерний поток попадает в родительский и убивает ОС высоким приоритетом; - если вызвать Free() "повторно" (не зная про автоFree) - ПО зависает на этой строке; - проверить, был ли ранее вызов Free() или Terminate(), - нет функционала; - если не использовать Free(), а просто оставлять потоки с Sleep(10000000000) в конце (нет доверия Suspend(), т.к. глючит Suspended), - приложение работает, закрывается крестиком (лишь влияние потоков друг на друга увеличивает время работы); - поэтому вызов Free() - разумная, но крайняя мера: стабильность работы и расчётов важнее скорости (хотя скорость - второй по значимости параметр); - вывод: пусть потоки со Sleep() внутри - плодятся... Но здесь - я всё-таки рискнул с Free. И... - и нихрена второе время выполнения не стало хоть примерно похоже на первое: всё так же сильно выше; - не плодящиеся потоки тормозят повторное выполнение кода, а что-то ещё; - и delete объекту потока уже не сделаешь: Free() уже напакостила; - и тут - озарение: если Free() мешает delete - пусть её не станет!; - в итоге, delete прекрасно уничтожает потоки без Free(), но время не перестало расти при повторных расчётах; - значит, это что-то ещё... Железо и ОС: - и Windows, и Linux - любят перекидывать активные задачи между логическими процессорами. В Linux это видно особенно явно: 2 из 4 загружено - хоп, разгрузились - загрузились 2 соседних; - не доказано, что открытый диспетчер задач увеличивает время работы программы; - выставление в Windows 10 режима совместимости с Windows 95 - все потоки накладываются на родительский - ОС виснет намертво; - а вот выставление режима совместимости с Windows XP SP2 - решило проблему скачков времени работы туда-сюда (погрешность стала ~3%); - нужно тестировать скорость работы как минимум на 3 разных ЦП: результаты непредсказуемы. Ещё вчера на одном ЦП было время выполнения 200с - стало 296с, а на другом было 290с, а стало 260с. Вот и думай, что изменилось. */ (добавлено 03.07.2026) Сюр возвёлся в квадрат - поэтому именно данный материал надо заканчивать, отложив чистовую разработку модуля многопоточности на время. Выяснилось, что как ни играйся с элементами родительского потока - реакция разных ЦП на эти игры разные. Один ЦП ускорится, второй замедлится - причём полная алогичность: например, уменьшение нагрузки на родительский поток - приводит к увеличению времени выполнения дочерних. Что пробовалось: - выставление приоритета реального времени для самого приложения - никаких изменений; - проверка в цикле нового чекбокса на чекнутость - разная реакция ЦП; - полное засыпание родительского потока - разная реакция ЦП; - вообще не слежение за потоками в родительском (тупо запуск дочерних потоков и ожидание - потоки сами возвращают время своей работы) - разная реакция ЦП (причём 2 из 3 - в сторону замедления - полный абсурд); - отключение именно визуального слежения за потоками (подкраска лабелов) - разная реакция ЦП. Значит, и класс потока, и модуль работы с потоками требуют серьёзных доработок: - обязательное введение сохранения времени работы каждого потока; - создание функции именно внутри модуля, возвращающей массив данных: нулевой элемент (не все потоки остановлены как завершившие работу) и остальные (конкретный поток не остановлен). Создание функции именно внутри модуля, убивающей все потоки и очищающей память; - создание теста времени Sleep() и частоты вызова ProcessMessages() в родительском потоке: если для каждого ЦП разное время выполнения и алогичность его поведения - измерять по факту на каждом ПК. Здесь можно зацепиться за 2 времени сразу, как факта корректности работы алгоритма: 260с на i5-10400 и 200с на E5-2696 V2; - добавить булев параметр и счётчик количества вызова циклов внутри потока: облегчённая перепроверка самого себя на правильность распределения задачи между потоками. Добавить и тест, имитирующий количество потоков 1-N и выдающий количество итераций для начального цикла for (причём, не расчётные числа - а факт отработки цикла). Доработка, которая не может быть реализована, ввиду недостатка IQ или накопившейся усталости. Автоматическое перераспределение задач между потоками: - при равной нагрузке - каждый из потоков хаотично завершается то быстрее, то медленнее. И возникает ситуация: поток остановился и стоит, остальные работают - поток простаивает зря; - чем больше потоков завершило обработку своей порции данных - тем больше неоптимальность использования ЦП получается; - в случае прошлого проекта, вычисления простых чисел, проблема решалась просто: вычислил простое число - не останавливайся, считай следующее - пока общий счётчик простых чисел не достигнет N. В результате, прирост скорости был получен просто феноменальный; - здесь же - нужно при условных 11 потоках: разбивать задачу на 100 частей, а не на 11 (ну не получается тут не разбивать задачу на части). И кормить следующую порцию данных остановившемуся потоку сразу же, как он остановился. Также возникнет вопрос: создавать новый поток или пытаться внутри текущего потока какой-нибудь goto mark_Begin реализовать; - эту доработку нужно реализовывать последней из всех вышеуказанных и придумываемых в будущем. А пока - просто скрин, как потоки хаотично завершаются (здесь всё началось с 9-го). В данном примере - максимальная погрешность уравнений прямых уже посчитана каким-то из завершившихся потоков. Остальные потоки - данную величину не превысят (это известно только потому, что данная величина известна заранее, - часами высчитанная на одном потоке). Ну и потратят на E5-2696 V2 332с вместо 200с. 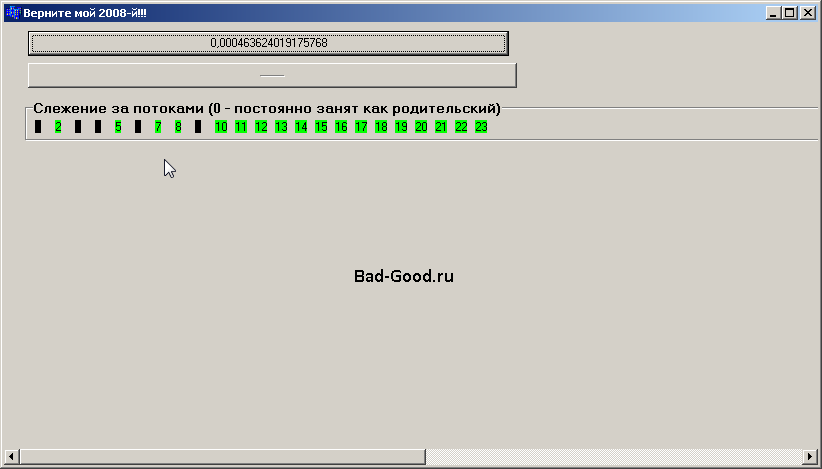 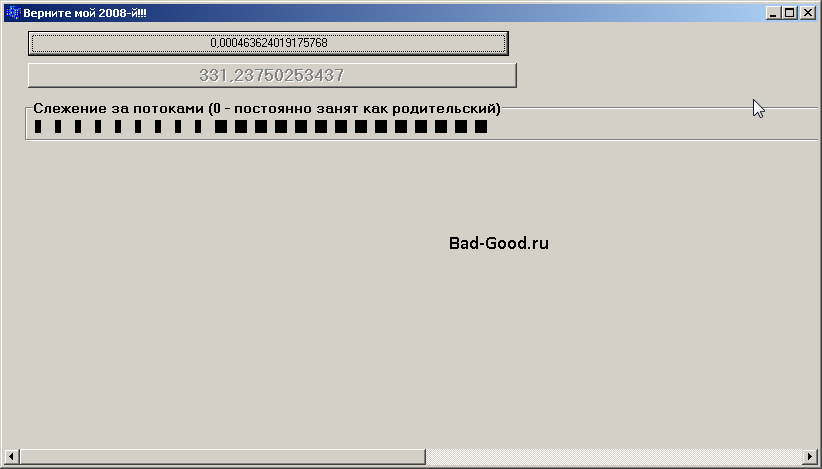 |
| Обновлено ( 04.07.2026 04:41 ) |